
Python基础笔记3
ps:对应教程day9- 1、列表的内存结构 mylist=[1,2,3,4,5,6] #mylist是一个多个变量组成的集合,每个变量可以存储不同的地址不同类型的变量的地址 可以改变其中每个变量的值,此时并不会改变这个列表的地址。 每个元...
ps:对应教程day9- 1、列表的内存结构 mylist=[1,2,3,4,5,6] #mylist是一个多个变量组成的集合,每个变量可以存储不同的地址不同类型的变量的地址 可以改变其中每个变量的值,此时并不会改变这个列表的地址。 每个元...
1、函数的本质是地址 2、函数返回值可以当作参数使用 3、函数内部的局部变量加上global,就会引用全局 def go(): global num num = 3 print(num,id(num)) 4、函数可以无限嵌套 def Tes...
不知道烂尾了多少次的Python学习计划,2019年争取把这个flag拔掉。课程为尹成python。 基础部分分成了27天,从输入输出到mysql数据库编程,这个日志记录这一部分认为重要的地方。 1、 常量不能被赋值,下面这个是错的 13=...
在Ubuntu18.01上配置时发现有一点区别,本机已经不带python2了 参考:https://blog.csdn.net/m0_38007695/article/details/83151861 安装 pip3 install vir...
import pandas as pd import numpy as np pd.set_option('display.max_columns', None) pd.set_option('display.width', 1000) t...
涉及知识 熵 熵表明的是一个事物的混乱程度,熵越大,混乱程度越高,熵越小,表明混乱程度越低。信息熵的概念也是一样的,就是用来表明信息的混乱程度,我们选择一个树根的时候,最好的情况肯定是通过这个属性把数据分成几类以后,这些数据的熵越小越好,因...
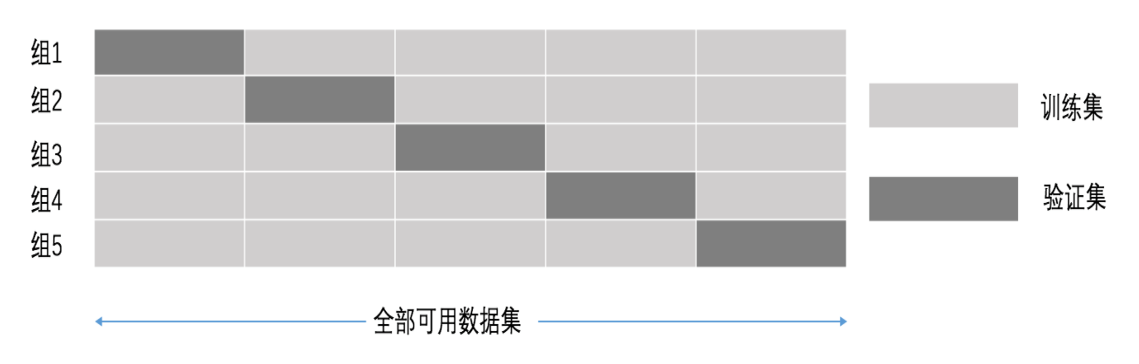
交叉验证 交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。 超参数搜索-网格搜索 通常...
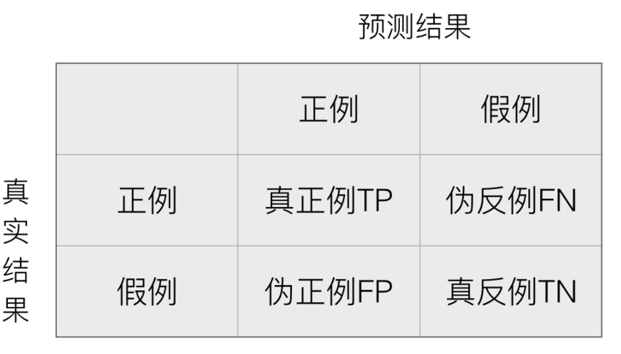
资料来源于PPT… 准确率 estimator.score()一般最常见使用的是准确率,即预测结果正确的百分比 混淆矩阵 在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)...
参考 https://blog.csdn.net/qq_35082030/article/details/70211552 fetch_20newsgroups是sklearn中内置的一个数据集。案例是一个新闻标题分类,整个过程概括起来分为...
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 ...