
Pandas基础
Pandas的数据结构 Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame Series Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成...
Pandas的数据结构 Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame Series Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成...
入门可以参考https://morvanzhou.github.io/tutorials/data-manipulation/np-pd/ 先占个坑 20180920开始填坑 Numpy:提供了一个在Python中做科学计算的基础库,重在数...
1 from matplotlib import pyplot as plt #导入 x = range(2,26,2) y = [15,13,14.5,17,20,25,26,26,27,22,18,15] #分别定义了X,Y坐标 #设置...
1.对于使用xpath,css选择器提取出来的对象,需要使用.extract()方法取值,常常使用.extract()[0] ,但是这种用法当xpath写错,提取不到东西是会返回一个空列表。可以使用.extract_first() 方法,提...
开始 导入 scrapy 模块, 并创建一个 spider 的 class. 并继承 scrapy.Spider。(使用默认模板就好) parse函数 def parse(self, response): urls = response.c...
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完...
这是一个使用scrapy框架的知乎爬虫,项目地址https://github.com/GZhangjl/zhihu_spider 其中通过selenium保存cookie,之前用scrapy提取的cookie一直不正确,所以把这一段代码拷贝...
2018/8/28更新,填坑完毕,改用selenium 点击此处 先挖一个坑,过一阵再填坑 def check_login(self, response): ''' cookie_jar.extract_cookies(response, ...
切片 用于取一个list或tuple的部分元素 L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack'] >>> L[0:3] #从索引0开始取,直到索引3为止,但不包括索引3 ['...
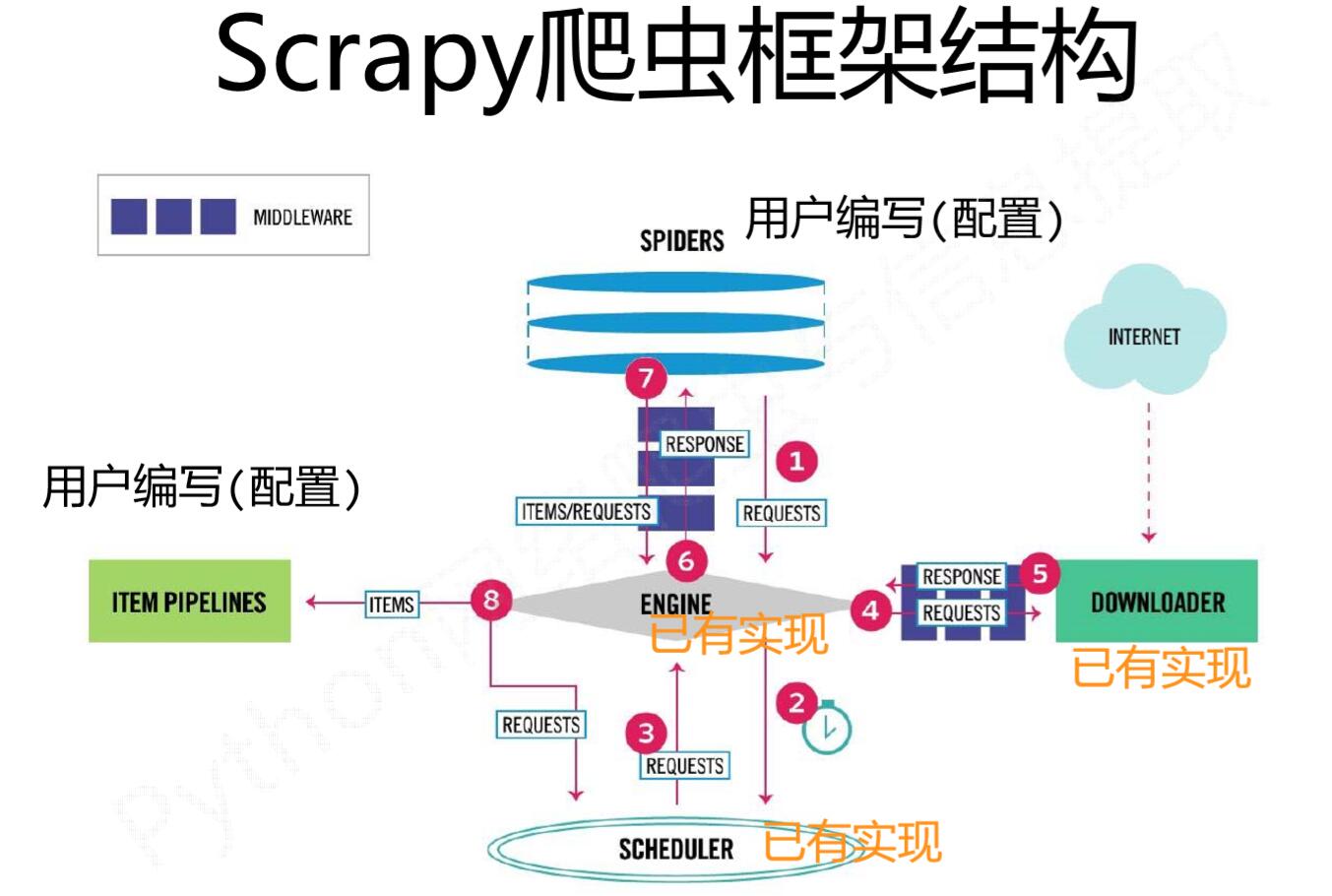
整体架构 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。 下载器(Downloader),用于下载网页内容,并将...