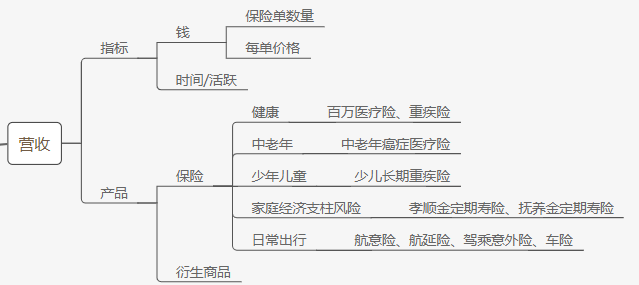
这是一个使用scrapy框架的知乎爬虫,项目地址https://github.com/GZhangjl/zhihu_spider
其中通过selenium保存cookie,之前用scrapy提取的cookie一直不正确,所以把这一段代码拷贝出来学习
def start_requests(self):
from selenium import webdriver
# 启动浏览器测试驱动
# 原来是使用的最新版chrome以及最新版chromedriver会出现grant_type错误,经查为知乎开始在最近使用OAuth认证。经测试,暂时较低
# 版本的chrome以及相应驱动可以运行
web_driver = webdriver.Chrome(r'C:\Users\zhang\Desktop\chromedriver_win32(1)\chromedriver.exe', )
web_driver.get('https://www.zhihu.com/signin')
web_driver.find_element_by_css_selector('.SignFlow-accountInput.Input-wrapper input').send_keys('****') # 输入账号
web_driver.find_element_by_css_selector('.SignFlow-password input').send_keys('****') # 输入密码
# 网上普遍的声音是既然已经在使用Selenium了,那这些难办的验证码(这里指比如倒立文字验证码)直接预留时间手工点就行了
# 原来有设想将开源第三方库zheye接入spider,但是在Selenium下很难做到,同时在有浏览器界面的情况下也显得没有必要
time.sleep(5)
web_driver.find_element_by_css_selector('[type=submit]').click()
time.sleep(5)
# “系统检测到您的帐号或IP存在异常流量,请进行验证用于确认这些请求不是自动程序发出的”
# 在同一ip(或同一账号)频繁访问知乎后,会被检测到疑似爬虫,需要验证码确认,以下为在模拟登陆后就出现验证码确认的情况的处理代码,
# 由于云打码的接入可能需要收费,所以暂时使用了自动显示验证码图片,然后可以手工往Console输入验证码的方式进行(虽然这样做跟直接在
# 模拟浏览器中直接输入验证码没区别)
try:
warn = web_driver.find_element_by_css_selector('.Unhuman-tip').text
except:
loger.debug('未检测出异常')
else:
loger.debug("CAPTCHA WARNING:{warn}".format(warn=warn))
page_html = web_driver.page_source
xpath_str = '//*[@id="root"]/div/div[2]/section/div/img/@src'
captcha_text = self.input_captcha('zhihu.com', page_html, xpath_str)
web_driver.find_element_by_css_selector('div.Unhuman-input>input').send_keys(captcha_text)
web_driver.find_element_by_css_selector('section.Unhuman-verificationCode>button').click()
time.sleep(10)
cookies = web_driver.get_cookies()
web_driver.close()
cookies_dict = {}
for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
with open('./cookies/zhihu_cookies.json', 'w') as f:
json.dump(cookies_dict, f)
yield Request(url=self.start_urls[0], callback=self.parse, dont_filter=True, headers=self.headers, cookies=cookies_dict)
# 该方法主要用于爬虫被检测到后验证码页面的解析和操作
def input_captcha(self, url, body_str, xpath_str):
from base64 import b64decode
from PIL import Image
html_response = HtmlResponse(url=url, body=body_str, encoding='utf8')
captcha_uri = html_response.xpath(xpath_str).extract_first()
captcha = b64decode(captcha_uri.replace('\n', '').partition(',')[-1])
with open('./utils/captcha.gif','wb') as p:
p.write(captcha)
with Image.open('./utils/captcha.png') as img:
img.show()
captcha_text = input('请输入显示验证码:')
return captcha_text