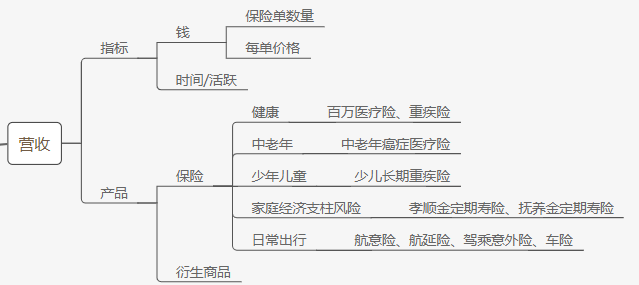
整体架构
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
数据流
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
参考
- https://www.jianshu.com/p/a8aad3bf4dc4
两篇好文
- https://cuiqingcai.com/3472.html
- https://blog.csdn.net/ReeeeeeStart/article/details/79327359
框架结构
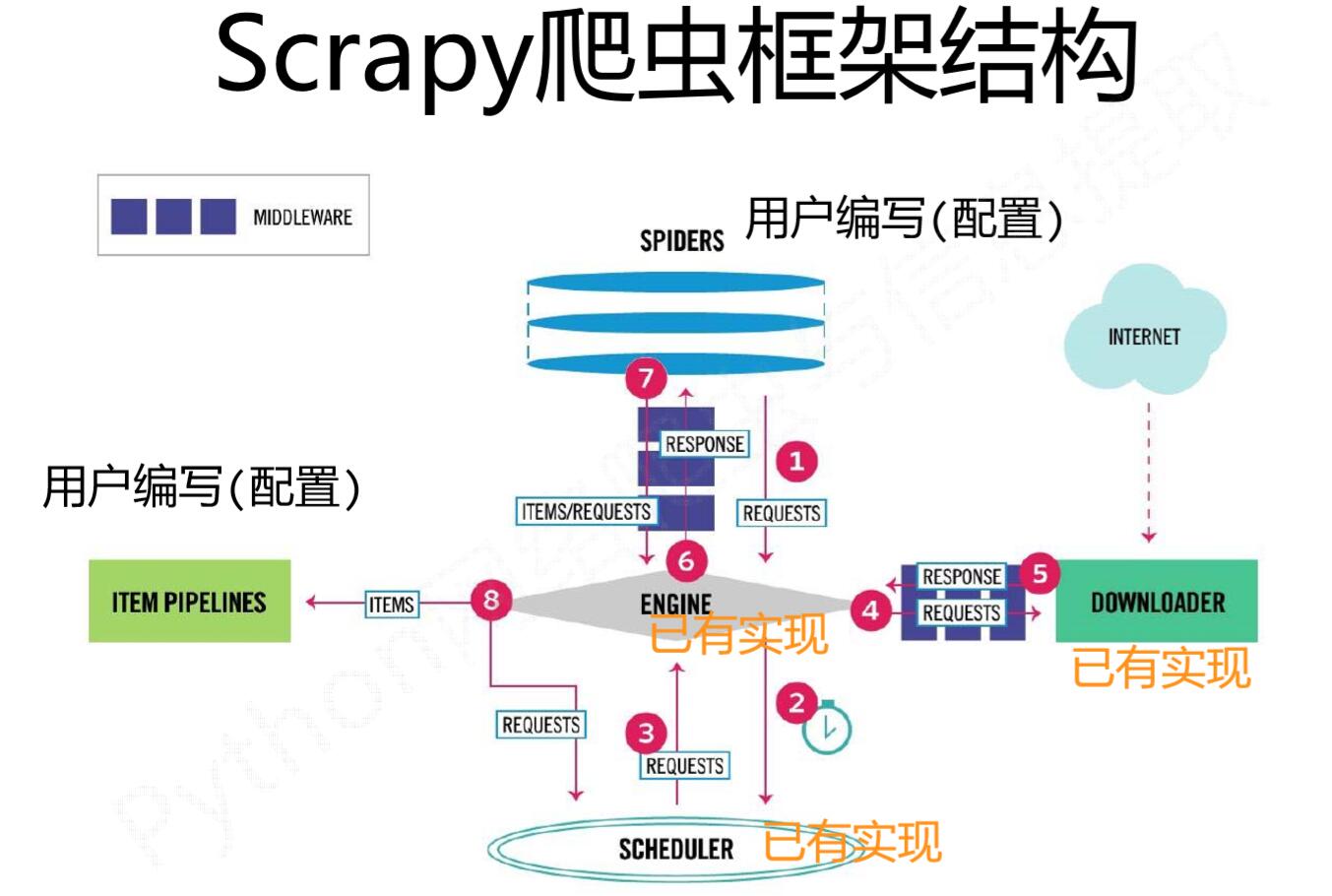
数据流(requests,response)的三个路径 :
第一条路径:
① :Engine从Spider处获得爬取请求(Request)
② :Engine将爬取请求转发给Scheduler,用于调度
第二条路径:
③ :Engine从Scheduler处获得下一个要爬取的请求
④ :Engine将爬取请求通过中间件发送给Downloader
⑤ :爬取网页后,Downloader形成响应(Response) 通过中间件发给Engine
⑥ : Engine将收到的响应通过中间件发送给Spider处理
第三条路径:
⑦ :Spider处理响应后产生爬取项(scraped Item) 和新的爬取请求(Requests)给Engine
⑧ :Engine将爬取项发送给Item Pipeline(框架出口)并且Engine将爬取请求发送给Scheduler
数据流的出入口:
Engine控制各模块数据流,不间断从Scheduler处 获得爬取请求,直至请求为空
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
各模块(结构)的作用:
Spider(需要用户编写配置代码):
- (1)解析Downloader返回的响应(Response)
- (2)产生爬取项(scraped item)
- (3)产生额外的爬取请求(Request)
Item Pipelines (需要用户编写配置代码):
- (1)以流水线方式处理Spider产生的爬取项
- (2)由一组操作顺序组成,类似流水线,每个操 作是一个Item Pipeline类型
- (3)可能操作包括:清理、检验和查重爬取项中 的HTML数据、将数据存储到数据库
Engine(不需要用户修改):
- (1)控制所有模块之间的数据流
- (2)根据条件触发事件
Downloader(不需要用户修改): 根据请求下载网页
Scheduler(不需要用户修改): 对所有爬取请求进行调度管理
Downloader Middleware(用户可以编写配置代码):
- 目的:实施Engine、Scheduler和Downloader 之间进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应
Spider Middleware(用户可以编写配置代码):
- 目的:对请求和爬取项的再处理
- 功能:修改、丢弃、新增请求或爬取项