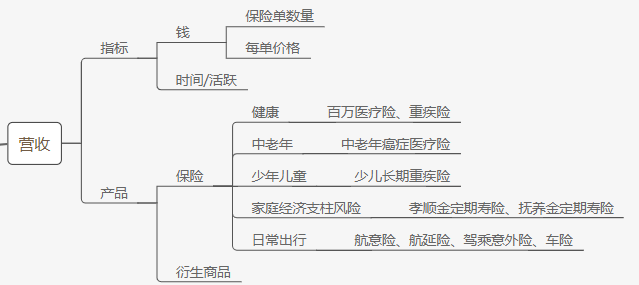
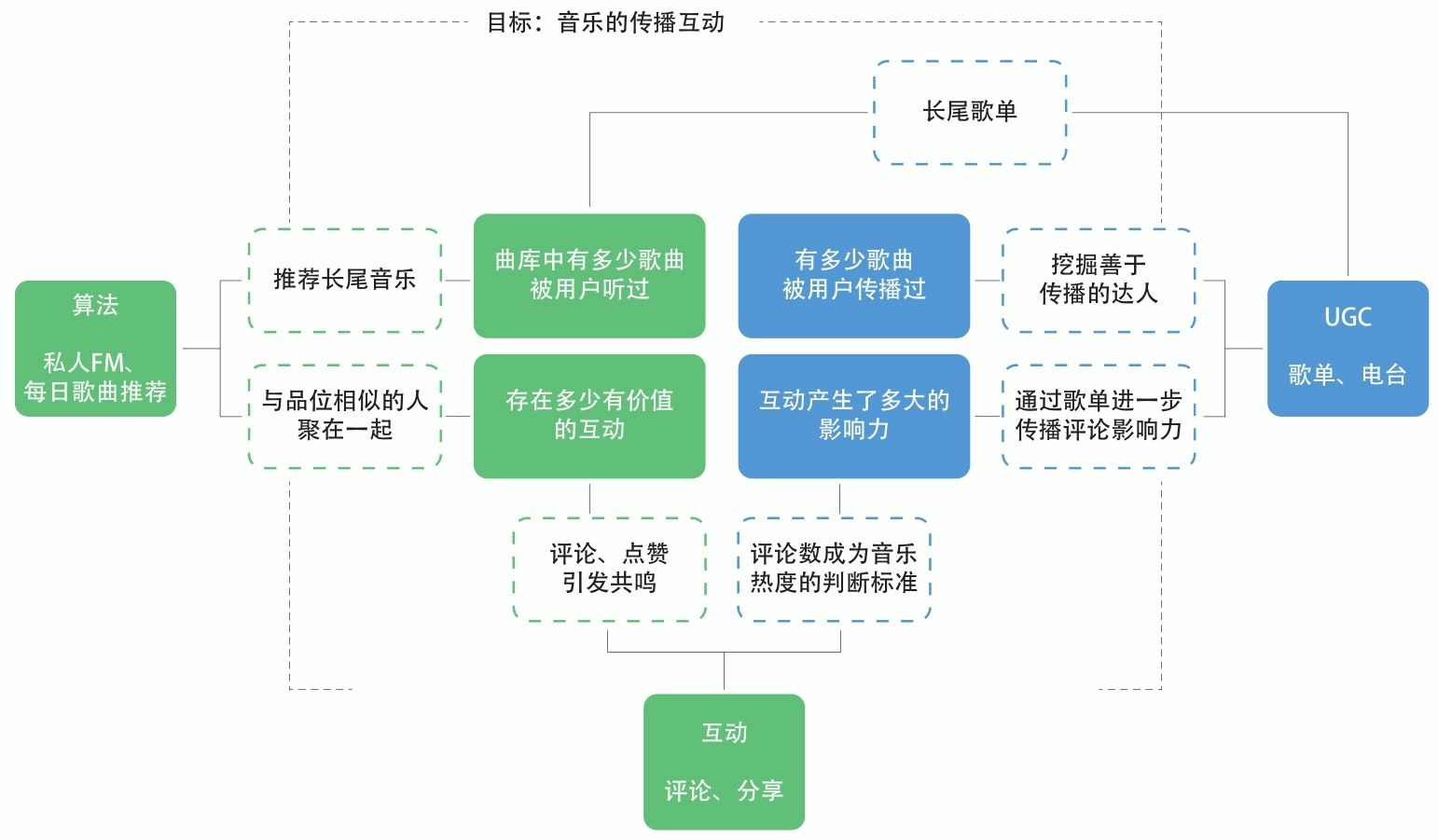
20180926更新
K近邻算法是非常直观的机器学习模型,我们可以发现K近邻算法没有参数训练过程,也就是说,我们没有通过任何学习算法分析训练数据,而只是根据测试样本训练数据的分布直接作出分类决策。因此,K近邻属于无参数模型中非常简单一种。
20180924更新:
最初的内容只是看课件ppt,有些东西不明白,搜到了一篇文章
- https://blog.csdn.net/liqiutuoyuan/article/details/77073689
kNN描述
kNN是一种基本的分类和回归方法。kNN的输入是测试数据和训练样本数据集(换言之,输入测试集与训练集),输出是测试样本的类别。kNN没有显示的训练过程,在测试时,计算测试样本和所有训练样本的距离,根据最近的K个训练样本的类别,通过多数投票的方式进行预测。
跪了后面都看不懂了…
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
两个样本的距离可以通过如下公式计算,又叫欧式距离
比如说,a(a1,a2,a3),b(b1,b2,b3)
√(〖(𝑎1−𝑏1)〗^2+〖(𝑎2−𝑏2)〗^2+〖(𝑎3−𝑏3)〗^2 )
k近邻算法:需要做标准化处理
sklearn k-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
案例
https://www.kaggle.com/c/facebook-v-predicting-check-ins/