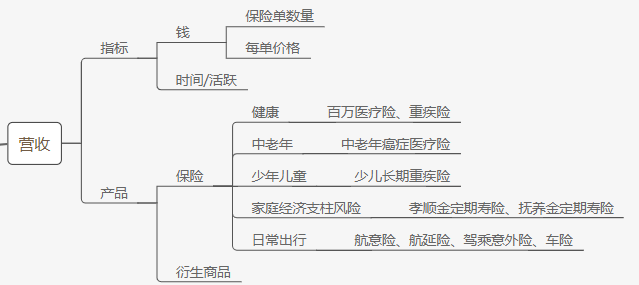
完全按照此大佬的代码进行测试,其中有三处json报格式错误,加上一个decode方法即可
.decode('utf-8')
# -*- coding: utf-8 -*-
__author__ = 'Mark'
__date__ = '2018/4/15 10:18'
import hmac
import json
import scrapy
import time
import base64
from hashlib import sha1
class ZhihuLoginSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
headers = {
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com/signup?next=%2F',
'User-Agent': agent,
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
}
grant_type = 'password'
client_id = 'c3cef7c66a1843f8b3a9e6a1e3160e20'
source = 'com.zhihu.web'
timestamp = str(int(time.time() * 1000))
timestamp2 = str(time.time() * 1000)
print(timestamp2)
def get_signature(self, grant_type, client_id, source, timestamp):
"""處理簽名"""
hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', None, sha1)
hm.update(str.encode(grant_type))
hm.update(str.encode(client_id))
hm.update(str.encode(source))
hm.update(str.encode(timestamp))
return str(hm.hexdigest())
def parse(self, response):
print(response.body.decode("utf-8"))
def start_requests(self):
yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers, callback=self.is_need_capture)
def is_need_capture(self, response):
print(response.text)
need_cap = json.loads(response.body.decode('utf-8'))['show_captcha']
print(need_cap)
if need_cap:
print('需要驗證碼')
yield scrapy.Request(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers,
callback=self.capture,
method='PUT'
)
else:
print('不需要驗證碼')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 輸入知乎用户名(手机号)
"password": "", # 輸入知乎密碼
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 獲取簽名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": "baidu"
}
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)
# yield scrapy.Request('https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000),
# headers=self.headers, callback=self.capture, meta={"resp": response})
# yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
# headers=self.headers, callback=self.capture, meta={"resp": response},dont_filter=True)
def capture(self, response):
# print(response.body)
try:
img = json.loads(response.body.decode('utf-8'))['img_base64']
except ValueError:
print('獲取img_base64的值失敗!')
else:
img = img.encode('utf8')
img_data = base64.b64decode(img)
with open('zhihu_capture.gif', 'wb') as f:
f.write(img_data)
f.close()
captcha = input('請輸入驗證碼:')
post_data = {
'input_text': captcha
}
yield scrapy.FormRequest(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
formdata=post_data,
callback=self.captcha_login,
headers=self.headers
)
def captcha_login(self, response):
try:
cap_result = json.loads(response.body.decode('utf-8'))['success']
print(cap_result)
except ValueError:
print('關於驗證碼的POST請求響應失敗!')
else:
if cap_result:
print('驗證成功!')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 輸入知乎用户名(手机号)
"password": "", # 輸入知乎密碼
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 獲取簽名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": ""
}
headers = self.headers
headers.update({
'Origin': 'https://www.zhihu.com',
'Pragma': 'no - cache',
'Cache-Control': 'no - cache'
})
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=headers,
callback=self.check_login
)
def check_login(self, response):
# 驗證是否登錄成功
text_json = json.loads(response.text)
print(text_json)
yield scrapy.Request('https://www.zhihu.com/inbox', headers=self.headers)