【日常吃瓜】 20191221
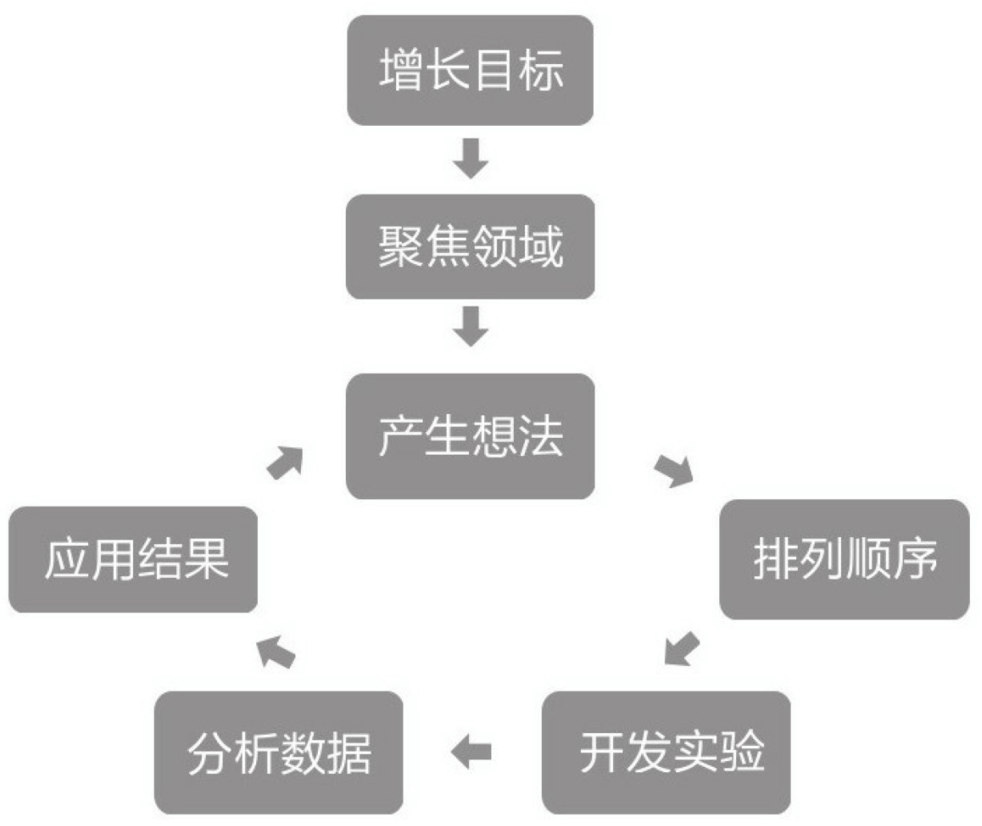
看了『Keep 的困顿与终局』这篇推文,水了个“读文笔记”。推文中提到了一个观点,大部分人对运动/健康的态度仍需要被引导。 我对这句话的理解是,在Keep的场景下,运动/健康是一个弱需求,所以用户对健康的态度需要被引导。联想到昨天看到了另外...
看了『Keep 的困顿与终局』这篇推文,水了个“读文笔记”。推文中提到了一个观点,大部分人对运动/健康的态度仍需要被引导。 我对这句话的理解是,在Keep的场景下,运动/健康是一个弱需求,所以用户对健康的态度需要被引导。联想到昨天看到了另外...
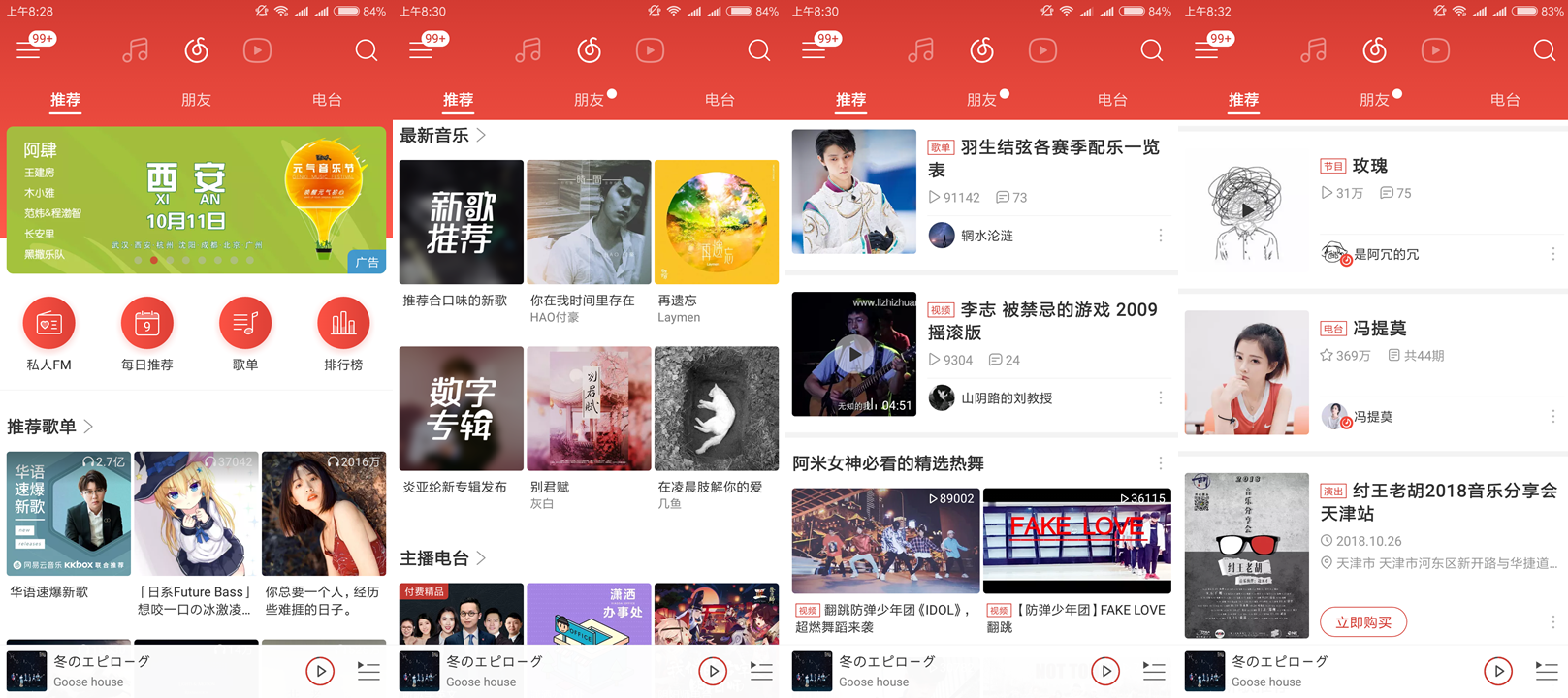
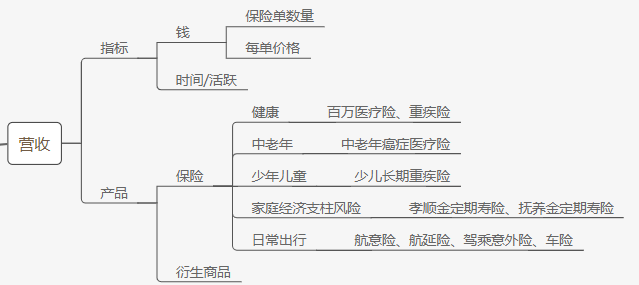
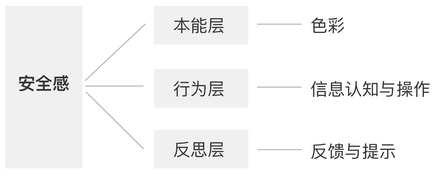
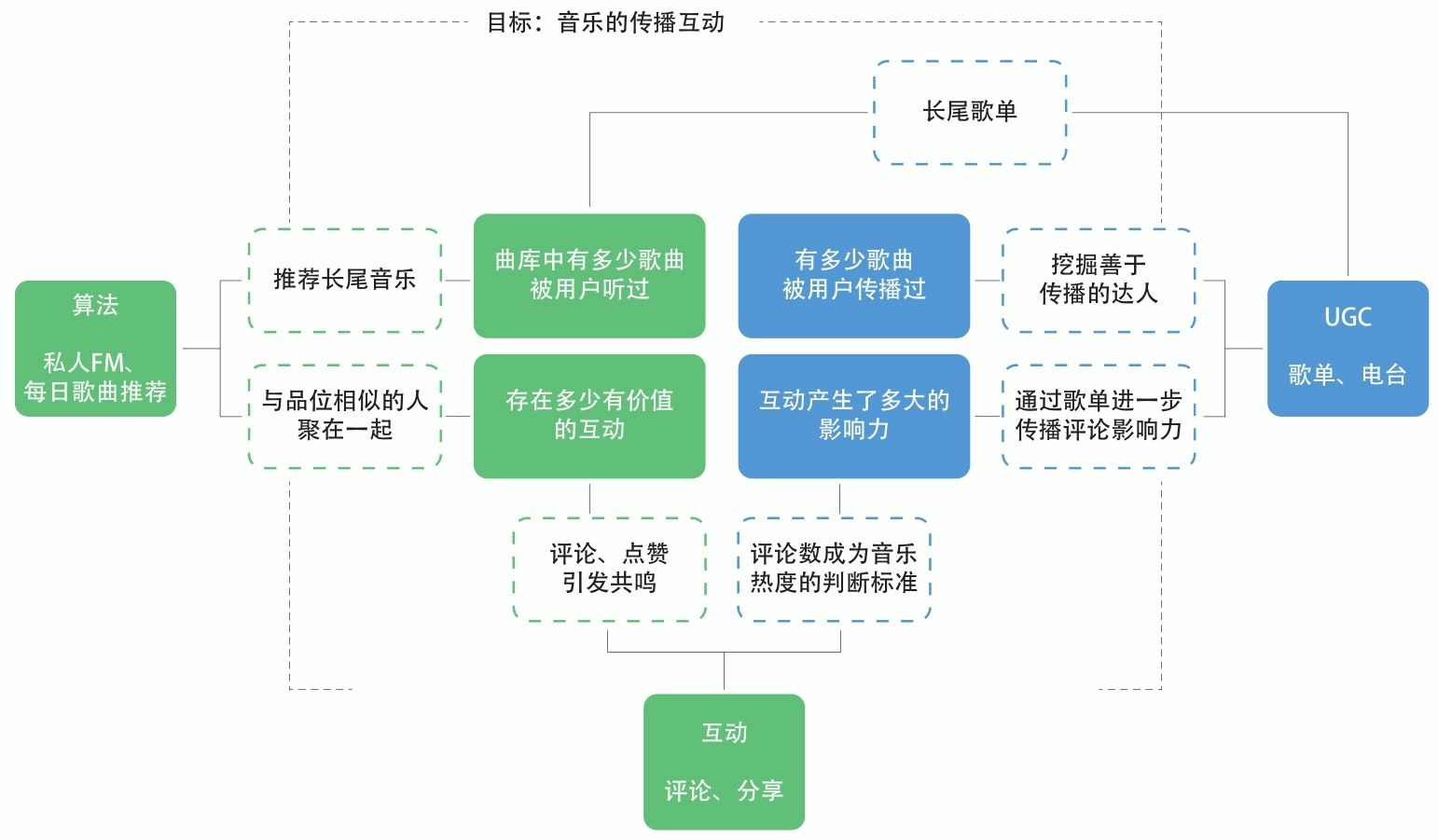
利用零散时间持续撰写中… 这是一个自己留给自己的作业,试图通过分析市场上现有的产品来训练自己的分析能力。因为自己是网易云音乐的重度用户,所以就选择分析网易云音乐。 本文是第一篇,试图通过分析网易云音乐安卓端APP的一些设计和逻辑...

在国庆假期前最后一个工作日去参加了一个面试,老实说表现的并不是很好,背后的原因是知识储备量不够和训练不足。也得到了很多的建议,其中有一条是看《金字塔原理》。这本书并不是很容易看,怎么讲,有点啰嗦…查找相关资料时偶然发现了另外一篇...

参考 https://blog.csdn.net/qq_35082030/article/details/70211552 fetch_20newsgroups是sklearn中内置的一个数据集。案例是一个新闻标题分类,整个过程概括起来分为...
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 ...
联合概率和条件概率 联合概率:包含多个条件,且所有条件同时成立的概率 记作:𝑃(𝐴,𝐵) 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率 记作:𝑃(𝐴|𝐵) 特性:P(A1,A2|B) = P(A1|B)P(A2|B) 注意:...
Dartmouth Class of 2015: It’s an honor to be at your tree stump. As your Commencement speaker, I have important responsi...
在有监督(supervise)的机器学习中,数据集常被分成2~3个,即:训练集(train set),验证集(validation set),测试集(test set)。 训练集:学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分...
使用 pandas.read_csv() 读取文件时出现了标题中的错误,搜索到两片文章,其中一个说是路径包含中文的原因。 https://blog.csdn.net/ArcheriesYe/article/details/77992412 ...
Windows下的文件目录路径使用反斜杠“\”来分隔。但是,和大多数语言一样,Python代码里面,反斜杠“\”是转义符,例如“\n”表示回车、“\t”表示制表符等等。这样,如果继续用windows习惯使用“\”表示文件路径,就会产生歧义。...
20180926更新 K近邻算法是非常直观的机器学习模型,我们可以发现K近邻算法没有参数训练过程,也就是说,我们没有通过任何学习算法分析训练数据,而只是根据测试样本训练数据的分布直接作出分类决策。因此,K近邻属于无参数模型中非常简单一种。 ...