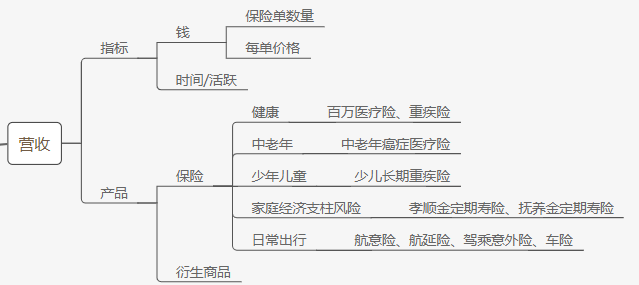
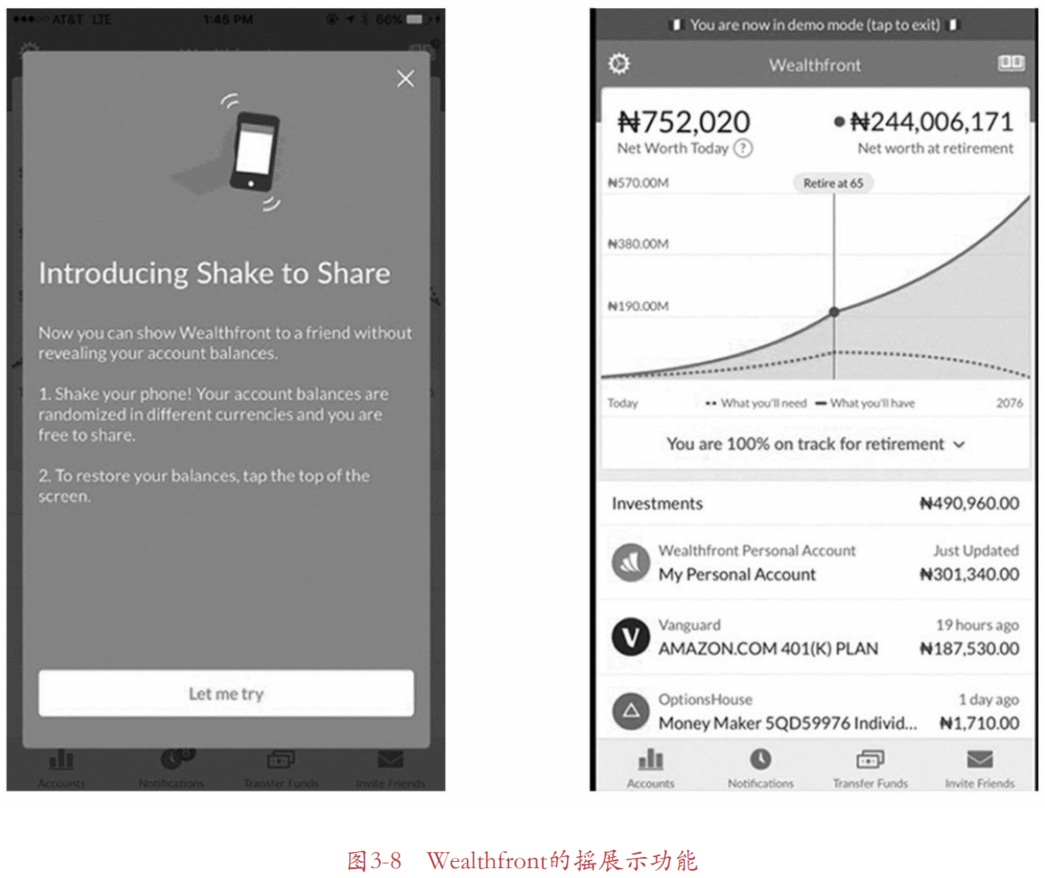
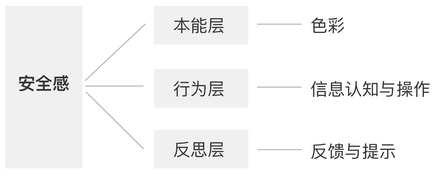
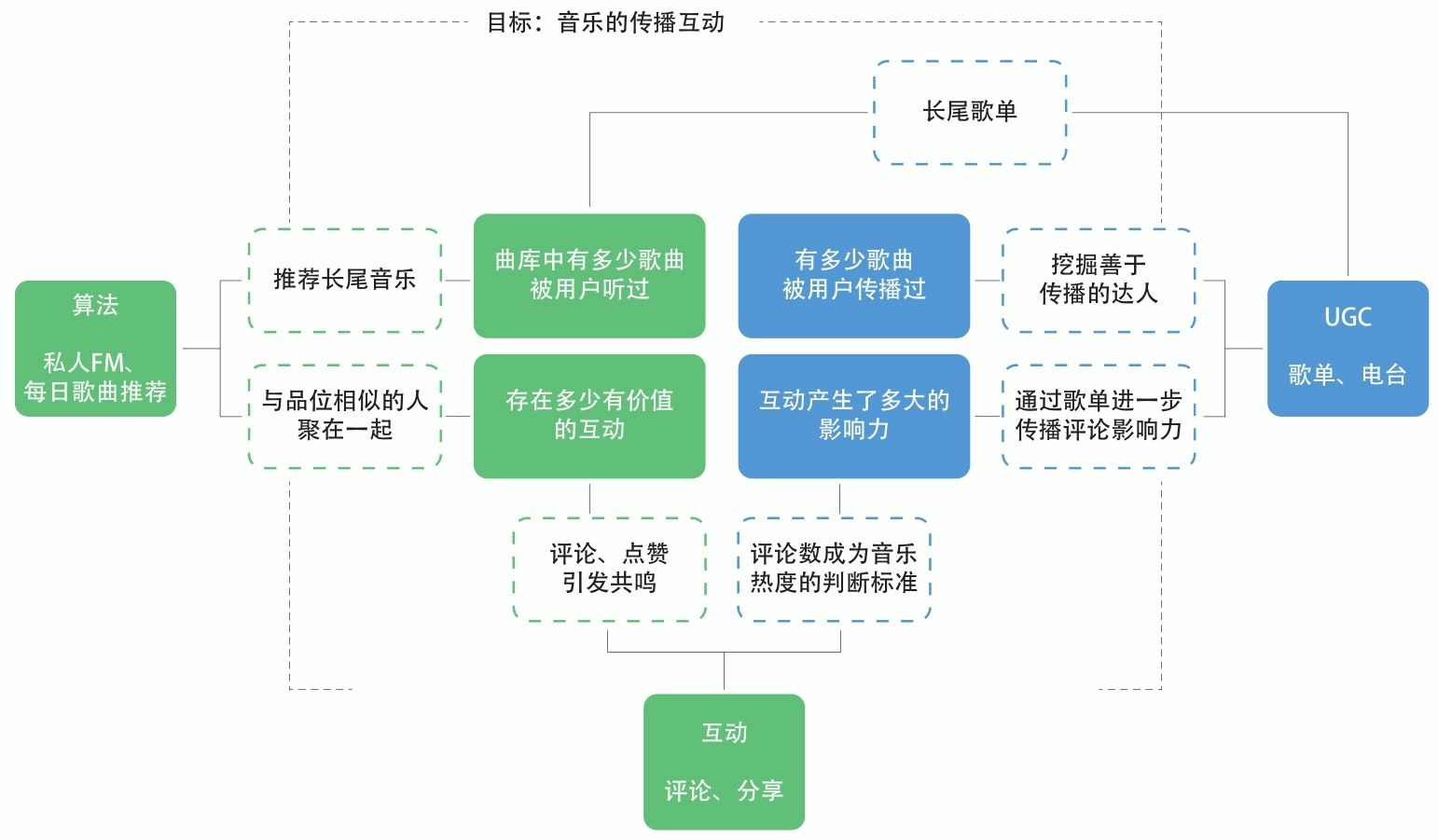
【日常吃瓜】 20191221
看了『Keep 的困顿与终局』这篇推文,水了个“读文笔记”。推文中提到了一个观点,大部分人对运动/健康的态度仍需要被引导。 我对这句话的理解是,在Keep的场景下,运动/健康是一个弱需求,所以用户对健康的态度需要被引导。联想到昨天看到了另外...
看了『Keep 的困顿与终局』这篇推文,水了个“读文笔记”。推文中提到了一个观点,大部分人对运动/健康的态度仍需要被引导。 我对这句话的理解是,在Keep的场景下,运动/健康是一个弱需求,所以用户对健康的态度需要被引导。联想到昨天看到了另外...

在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API 用于分类的估计器: sklearn.neighbors k-近邻算法 sklearn.naive_bayes...
监督学习 分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络 回归 线性回归、岭回归 标注 隐马尔可夫模型 无监督学习 聚类 k-means 监督学习 监督学习(英语:Supervised learning),可以由输入数...
PCA-主成分分析 本质:PCA是一种分析、简化数据集的技术 目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。 作用:可以削减回归分析或者聚类分析中特征的数量 步骤 初始化PCA,指定减少后的维度 调用fit_tran...
原因 冗余:部分特征的相关度高,容易消耗计算性能 噪声:部分特征对预测结果有负影响 特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只...
归一化 sklearn归一化API: sklearn.preprocessing.MinMaxScaler 步骤 实例化MinMaxScalar 通过fit_transform转换 缺点: 在特定场景下最大值最小值是变化的,另外,最大值与最...
Pandas的数据结构 Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame Series Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成...

1.小程序做出来了,准备填充内容 2.开始入坑数据分析和机器学习 3.今天精读了一篇高中的毕业演讲…哎…加油吧

Dr. Wong, Dr. Keough, Mrs. Novogroski, Ms. Curran, members of the board of education, family and friends of the graduate...
入门可以参考https://morvanzhou.github.io/tutorials/data-manipulation/np-pd/ 先占个坑 20180920开始填坑 Numpy:提供了一个在Python中做科学计算的基础库,重在数...
President Powers, Provost Fenves, Deans, members of the faculty, family and friends and most importantly, the class of 2...